Lista enlazada simple
Las listas enlazadas las podemos utilizar cuando necesitemos hacer varias operaciones de ingresar y eliminar elementos.
Tenemos que tomar en cuenta con algunos de los requisitos como:
- El tipo o tipos de datos que vamos a utilizar.
- Las estructuras o bases.
- El u
- so de la palabra typedef (palabra reservada de C y C++, que se utiliza para asignar un alias o sobrenombre a un tipo de dato, sin afectar el tipo).
- Los punteros.
- Las funciones usuario (que vendrían siendo las definidas por el mismo).
Como crear el modelo de un elemento de la lista
Tenemos que utilizar la palabra struct que nos servirá para agrupar variables de distinto tipo si asi de desea, bajo un mismo nombre.
Nuestro elemento de la lista tiene que tener un espacio de dato y un puntero siguiente, este puntero siguiente tiene que ser igual al tipo del elemento, si no, no se podrá seguir a ese elemento.
Este puntero siguiente permitirá el acceso al próximo elemento.
typedef struct ElementoLista {
char *dato;
struct ElementoLista *siguiente;
} Elemento;
Para poder tener el control de nuestra lista de preferencia tenemos que guardar algunos elementos, como el primer elemento, ultimo y número de elementos.
Para esto podemos utilizar otra estructura, aunque no es obligatorio, podemos utilizar variables.
typedef struct ListaIdentificar {
Elemento *inicio;
Elemento *fin;
int tamaño;
} Lista;
El puntero inicio tiene la dirección del primer elemento de la lista.
El puntero fin tiene la dirección del último elemento de la lista.
La variable tamaño tiene el número de elementos.
No importa la posición en la lista, pues los punteros inicio y fin siempre apuntaran al primer y ultimo elemento. Mientras que el campo tamaño tendrá el numero de elementos que contendrá la lista, sin importar la operación que se realice.
Modelo de la función:
void inicializacion (Lista *lista);
Esta operación se debe de hacer antes de alguna otra operación sobre la lista.
Esta inicializa el puntero inicio y el puntero fin con el puntero NULL, y el tamaño con el valor 0.
Función:
void inicializacion (Lista *lista){
lista->inicio = NULL;
lista->fin = NULL;
tamaño = 0;
}
Como insertar un elemento en la lista
Tenemos que seguir una serie de pasos para poder lograr esta tarea:
- Declarar el elemento a insertar.
- Asignar la memoria para el nuevo elemento.
- Rellenar el contenido del campo de datos.
- Actualizar los punteros hacia el primer y ultimo elemento si se necesita.
- Un caso particular: en una lista con un solo elemento, el primero es al mismo tiempo el último.
- Tenemos que actualizar el tamaño de la lista.
Existen varios casos para cuando queremos añadir un elemento a la lista:- 1. Inserción en una lista vacía
- 2. Inserción al inicio de la lista
- 3. Inserción al final de la lista
- 4. Inserción en otra parte de la lista.
Inserción en una lista vacía
Ejemplo de función:
int ins_en_lista_vacia (Lista *lista, char *dato);
La función devuelve 1 en caso de error, si no devuelve 0.
Etapas a seguir:- Asignar la memoria para el nuevo elemento.
- Rellenar el campo de datos del nuevo elemento.
- El puntero siguiente del nuevo elemento apuntará hacia NULL (debido a que la inserción esta hecha en una lista vacía se utiliza la dirección del puntero inicio con valor NULL).
- Los punteros inicio y fin apuntaran hacia el nuevo elemento.
- El tamaño se actualiza.
Lista vacía.
Dato ingresado en una lista vacía.
Función:
/* inserción en una lista vacía */
int ins_en_lista_vacia (Lista * lista, char *dato){
Element *nuevo_elemento;
if ((nuevo_elemento = (Element *) malloc (sizeof (Element))) == NULL)
return -1;
if ((nuevo _elemento->dato = (char *) malloc (50 * sizeof (char)))
== NULL)
return -1;
strcpy (nuevo_elemento->dato, dato);
nuevo_elemento->siguiente = NULL;
lista->inicio = nuevo_elemento;
lista->fin = nuevo_elemento;
lista->tamaño++;
return 0;
}
Inserción al inicio de la lista
Ejemplo de función:
int ins_inicio_lista (Lista *lista,char *dato);
La función devuelve -1 en caso de error, si no devuelve 0.
Etapas a seguir:- Asignar la memoria al nuevo elemento.
- Rellenar el campo de datos del nuevo elemento.
- El puntero siguiente del nuevo elemento apunta hacia el primer elemento.
- El puntero inicio apunta hacia el nuevo elemento.
- El puntero fin no cambia.
- El tamaño se incrementa.
Lista que no esta vacía y dato que deseamos insertar.
Empezando con la inserción.
Resultado de la inserción.
Función:
/* inserción al inicio de la lista */
int ins_inicio_lista (Lista * lista, char *dato){
Element *nuevo_elemento;
if ((nuevo_elemento = (Element *) malloc (sizeof (Element))) == NULL)
return -1;
if ((nuevo_elemento->dato = (char *) malloc (50 * sizeof (char)))
== NULL)
return -1;
strcpy (nuevo_elemento->dato, dato);
nuevo_elemento->siguiente = lista->inicio
lista->inicio = nuevo_elemento;
lista->tamaño++;
return 0;
}
Inserción al final de la lista
Ejemplo de función:
int ins_fin_lista (Lista *lista, Element *actual, char *dato);
La función devuelve -1 en caso de error, si no devuelve 0.
Etapas a seguir:- Asignar la memoria al nuevo elemento.
- Rellenar el campo de datos del nuevo elemento.
- El puntero siguiente del ultimo elemento apunta hacia el nuevo elemento.
- El puntero fin apunta hacia el nuevo elemento.
- El puntero inicio no cambia.
- El tamaño se incrementa.
Lista que no esta vacía y dato que se desea insertar.
Empezando con la inserción.
Resultado de la inserción.
Función:
/*inserción al final de la lista */
int ins_fin_lista (Lista * lista, Element * actual, char *dato){
Element *nuevo_elemento;
if ((nuevo_elemento = (Element *) malloc (sizeof (Element))) == NULL)
return -1;
if ((nuevo_elemento->dato = (char *) malloc (50 * sizeof (char)))
== NULL)
return -1;
strcpy (nuevo_elemento->dato, dato);
actual->siguiente = nuevo_elemento;
nuevo_elemento->siguiente = NULL;
lista->fin = nuevo_elemento;
lista->tamaño++;
return 0;
}
Inserción en otra parte de la lista
Ejemplo de función:
int ins_lista (Lista *lista, char *dato,int pos);
La función devuelve -1 en caso de error, si no devuelve 0.
Etapas a seguir:- Asignar la memoria al nuevo elemento.
- Rellenar el campo de datos del nuevo elemento.
- Elegir una posición en la lista (la inserción se hará después de haber elegido la posición).
- El puntero siguiente del nuevo elemento apunta hacia la dirección a la que apunta el puntero siguiente del elemento actual.
- El puntero siguiente del elemento actual apunta al nuevo elemento.
- Los punteros inicio y fin no cambian.
- El tamaño se incrementa en una unidad.
Lista no vacía y dato que se desea insertar.
Proceso de insertar.
Resultado de inserción en cualquier lugar de la tabla.
Función:
/* inserción en la posición solicitada */
int ins_lista (Lista * lista, char *dato, int pos){
if (lista->tamaño < 2)
return -1;
if (pos < 1 || pos >= lista->tamaño)
return -1;
Element *actual;
Element *nuevo_elemento;
int i;
if ((nuevo_elemento = (Element *) malloc (sizeof (Element))) == NULL)
return -1;
if ((nuevo_elemento->dato = (char *) malloc (50 * sizeof (char)))
== NULL)
return -1;
actual = lista->inicio;
for (i = 1; i < pos; ++i)
actual = actual->siguiente;
if (actual->siguiente == NULL)
return -1;
strcpy (nuevo_elemento->dato, dato);
nuevo_elemento->siguiente = actual->siguiente;
actual->siguiente = nuevo_elemento;
lista->tamaño++;
return 0;
Como eliminar un elemento en una lista
Tenemos que seguir estos pasos:
Usar un puntero temporal para guardar la dirección de los elementos que deseamos eliminar.
El elemento que deseamos eliminar se encuentra después del elemento actual.
Necesitamos apuntar el puntero siguiente del elemento actual hacia la dirección del puntero siguiente del elemento que se desea eliminar, tenemos que:
- Liberar la memoria ocupada por el elemento eliminado
- Actualizar el tamaño de la lista
Existen varios casos para la eliminación de datos:- Eliminación al inicio de la lista
- Eliminación en otra parte de la lista
Eliminar un elemento al inicio de la lista
Ejemplo de la función:
int sup_inicio (Lista *lista);
La función devuelve -1 en caso de error, si no devuelve 0.
Etapas a seguir:- El puntero sup_elem contendrá la dirección del primer elemento.
- El puntero inicio apuntara hacia el segundo elemento.
- El tamaño de la lista tendrá que disminuir un elemento.
Imagen que demuestra la eliminación al inicio de la lista.
Función:
/* eliminación al inicio de la lista */
int sup_inicio (Lista * lista){
if (lista->tamaño == 0)
return -1;
Element *sup_elemento;
sup_element = lista->inicio;
lista->inicio = lista->inicio->siguiente;
if (lista->tamaño == 1)
lista->fin = NULL;
free (sup_elemento->dato);
free (sup_elemento);
lista->tamaño--;
return 0;
}
Eliminar un elemento en otra parte de la lista
Ejemplo de función:
int sup_en_lista (Lista *lista, int pos);
La función devuelve -1 en caso de error, si no devuelve 0.
Etapas a seguir:- El puntero sup_elem tiene que contener la dirección hacia la que apunta el puntero siguiente del elemento actual.
- El puntero siguiente del elemento actual apuntara hacia el elemento al que apunta el puntero siguiente del elemento que sigue al elemento actual en la lista.
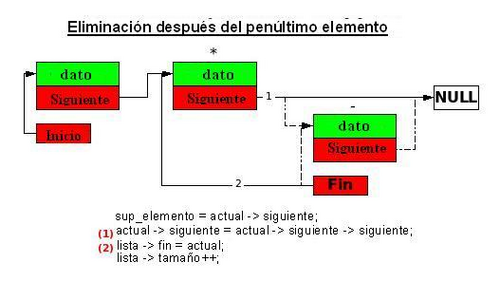
Si el elemento actual es el penúltimo elemento, el puntero fin se debe de actualizar.- El tamaño de la lista tendrá que disminuir en un elemento.
Imagen que demuestra la eliminación de una parte que se solicito.
Imagen que demuestra la eliminación después del penúltimo elemento de la lista.
Función:
/* eliminar un elemento después de la posición solicitada */
int sup_en_lista (Lista * lista, int pos){
if (lista->tamaño <= 1 || pos < 1 || pos >= lista->tamaño)
return -1;
int i;
Element *actual;
Element *sup_elemento;
actual = lista->inicio;
for (i = 1; i < pos; ++i)
actual = actual->siguiente;
sup_elemento = actual->siguiente;
actual->siguiente = actual->siguiente->siguiente;
if(actual->siguiente == NULL)
lista->fin = actual;
free (sup_elemento->dato);
free (sup_elemento);
lista->tamaño--;
return 0;
}
Referencias:
http://es.wikipedia.org/wiki/Lista_(inform%C3%A1tica)
http://es.kioskea.net/faq/2842-la-lista-enlazada-simple
http://www.programacionfacil.com/estructura_de_datos:listas_enlazadas
Las ultimas 3 imágenes tuve la necesidad de poner esas ya que no encontraba más, para la siguiente entrada que no encuentre imágenes las haré yo, como hice en mi entrada pasada referente a las listas.